Zu approximierende Funktion : ![]() (1)
(1)
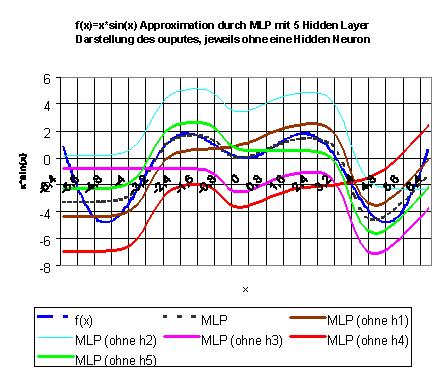 |
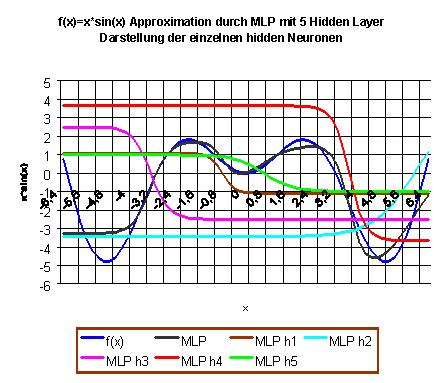 |
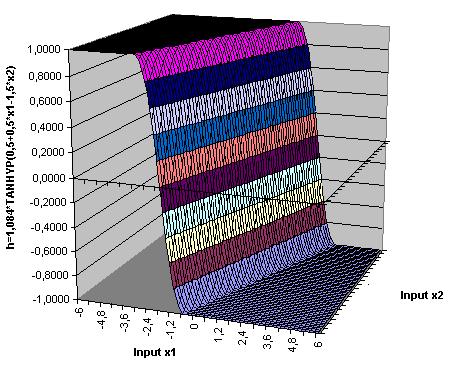 |
| Aktivierungsfunktion eines Hidden-Neurons für zwei Inputvariable h(x1,x2)=1,084*tanh(0.5+0.5*x1-1,5*x2) |
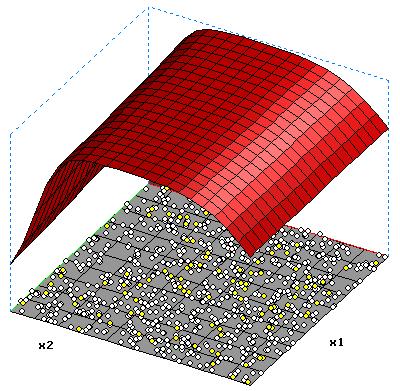 |
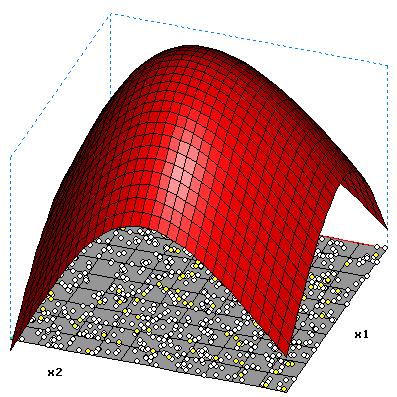
2 Hidden-Neuronen o= 0.046-0.870*tanh(-0.896+1.131*x1-0.247*x2)-0.967*tanh(-0.127-1.546*x1+0.363*x2) |
 |
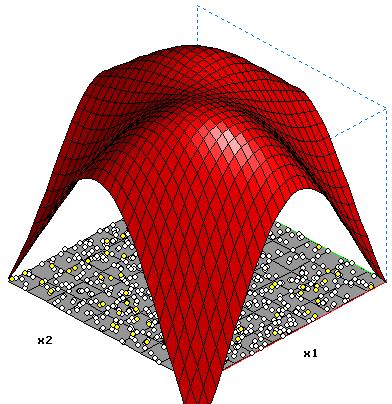
3 Hidden-Neuronen o= -2.081-1.446*tanh(-0.254-2.585*x1+0.497*x2)-1.244*tanh(-0.013+0.188*x1-2.654*x2)-1.713*tanh(-1.646+1.015*x1+0.855*x2) |
 |
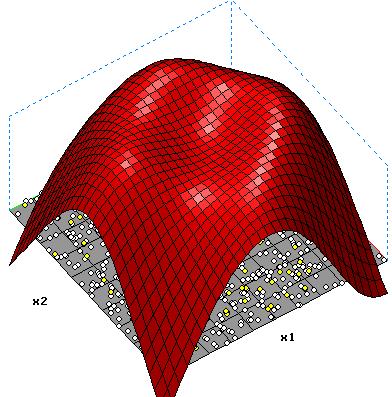
4 Hidden-Neuronen o= 1.578-1.718*tanh(-0.783-0.153*x1+1.159*x2) -1.702*tanh(-0.864-1.256*x1+0.101*x2)+1.321*tanh(2.061- 1.289*x1+1.378*x2) +1.371*tanh(-0.792-1.427*x1+1.354*x2) |
 |
10 Hidden-Neuronen |
Approximation anhand von Datenpunkten am Beispiel der XOR-Funktion
Xor ist eine Binäre Funktion (exklusives oder) die nicht linear seperabel ist und deshalb nicht von einem Singel-Layer-Perceptron erlernt werden kann.
Wertetabelle:
|
X1 |
X2 |
xor |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
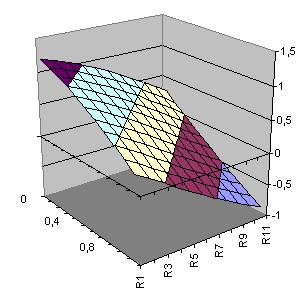
| Fläche Hidden-Neuron 1 h1(x1,x2)=-1.684*tanh(-0.917+0.759*x1+0.754*x2) |
Fläche Hidden-Neuron 2 h2(x1,x2)= -1.368*tanh(0.621-1.985*x1-1.957*x2) |
 |
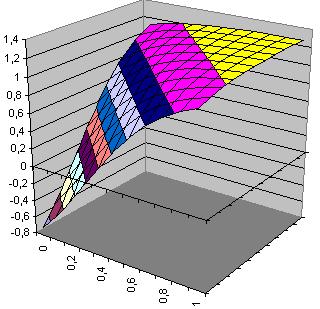 |

Xor(x1,x2)= -0.465+h1(x1,x2)+ h2(x1,x2)
Xor(x1,x2)= -0.465-
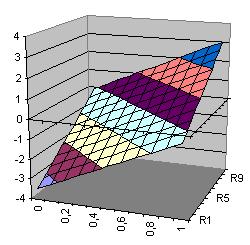
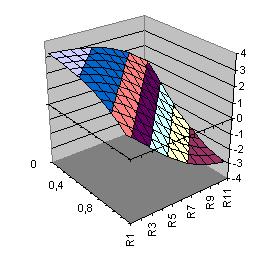
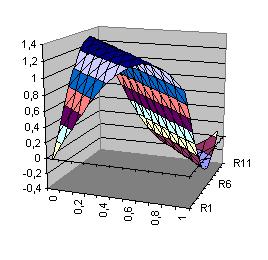
| Ebene Direktverbindungen Ebene(x1,x2)= 3.345+3.369*x1+3.093*x2 |
Fläche Hidden-Neuron h1(x1,x2)=-3.453*tanh(2.053+1.765*x1+1.675*x2) |
Ausgabefunktion Xor Xor(x1,x2)= 3.345-3.453*tanh(-2.053+1.765*x1+1.675*x2) +3.369*x1+3.093*x2 |
 |
 |
 |